Most legal agent failures are not actually agent failures

Why the deployments that 'failed' were never built to succeed, by Lorna Khemraz
The pattern nobody wants to name
Six weeks into the deployment, the legal ops team put the agent on pause. The routing was wrong. Requests that should have gone straight to a lawyer were sitting in a processing queue. Requests that needed no legal input at all were getting escalated. The lawyers had stopped trusting what came out of the shared inbox, which meant they had quietly stopped using it, and the team was back to sorting emails by hand. The tool got the blame.
I don’t think the tool was the problem.
What had happened in the weeks before go-live was roughly this: someone configured the agent over an afternoon, pointed it at the legal team’s shared mailbox, gave it a two-paragraph description of what the team handled, and waited for results. There was no routing logic documented beyond the obvious cases. No definition of what “urgent” meant in practice, or which business units had priority SLAs, or when a commercial request should go to the GC rather than a mid-level associate. Nobody reviewed the first fifty routing decisions against any rubric or gave the agent feedback on where it was wrong. The team measured nothing for the first three weeks, and then decided the results weren’t good enough and pulled back.

This pattern is not unusual. Forrester has found that 25% of planned enterprise AI spend is being deferred into 2027 because of ROI concerns. The ModelOp 2026 AI Governance Benchmark Report found that two-thirds of enterprises still rely on manual ROI tracking for their production AI. These numbers point at something I think the industry is reluctant to name clearly: a significant portion of the deployments that “failed” were never built to succeed.
A significant portion of the deployments that “failed” were never built to succeed.
🏗️ The wrong analogy
The standard framing for agent deployment treats it like software installation. You configure it, test it, and ship it. If the output isn’t right, the configuration is wrong or the software is flawed. The failure mode is technical, the fix is technical, and the person who made the decision stays largely insulated from the outcome.
What I find, looking at the actual pattern of deployments that work versus deployments that don’t, is that the analogy is wrong. Deploying an agent is closer to hiring and managing a team member, one who is extraordinarily fast, highly reliable within the scope of their instructions, and completely dependent on those instructions for any judgment about edge cases. The analogy isn’t perfect. But it is precise enough to be useful.
What would you actually do when you hire someone?
Think about what you would actually do if you hired someone to manage your legal team’s shared inbox, sixty to eighty requests a day, sorting what needs a lawyer, what can be handled by ops, what is genuinely urgent, and what can wait a week. You would not hand them the login and walk away. You would explain how the team actually works: which business units tend to send things that sound urgent but aren’t, which request types are always the GC’s call regardless of how they’re framed, how a supplier dispute is different from a routine contract request even when they arrive in identical-looking emails. You would review their first few weeks of decisions, flag the ones where their judgment differed from yours, and explain why. You would build their understanding of your organisation’s priorities gradually, by showing them what good looks like and correcting what isn’t. You would ask questions and expect them to ask questions back.
That process is onboarding. It is also, I think, the stage that most agent deployments skip entirely.
The comfortable explanation
The consequence is predictable, even if we resist calling it predictable in the moment. Vague instructions produce inconsistent output. An agent told to “route incoming legal requests to the right person” with no further context has no way to know that your organisation’s procurement team sends everything as “urgent” regardless of actual urgency, or that requests from one particular regional team almost always need a senior lawyer’s eye before anyone responds, or that a certain category of supplier query is legally routine but politically sensitive. It does the best it can with what it has, which means it applies general logic to a situation that runs on institutional logic the agent was never given. When the output doesn’t match what an experienced team member would have done, the conclusion is that the agent doesn’t work.
Sloppy instructions produce sloppy output. This is not a surprising result. But there is a meaningful gap between acknowledging that in principle and applying it in practice, partly because closing that gap requires a kind of accountability that is harder than switching vendors.
Sloppy instructions produce sloppy output. This is not a surprising result. But closing that gap requires a kind of accountability that is harder than switching vendors.
I have seen this pattern enough times now that I think there is something psychological going on, not just operational. Blaming the technology is easier than auditing the system. The technology is external. The system is yours. When a legal team deploys an agent with inadequate instructions, no monitoring, and no feedback loop, and then experiences poor output, the accurate diagnosis, “we did not build the system correctly,” is available but uncomfortable. The alternative, “the AI isn’t ready,” is also available and considerably more comfortable. Forrester’s numbers suggest many teams are choosing the second explanation and deferring.
⚖️ The accountability sits with whoever built the system
There is a systems thinking argument here that I find important and underused. When a leader builds a team that underperforms, we do not generally say the team failed. We ask what was missing from the system: the hiring criteria, the onboarding, the clarity of objectives, the feedback loops, the measurement framework. A leader who gives a team vague direction and then blames the team for vague results has misidentified where the problem lives. The accountability sits with whoever built the system.
The same logic applies to agents. An organisation that deploys a legal AI agent is responsible for the quality of the instructions that agent operates on, the monitoring that catches and corrects errors in the early period, the feedback loops that teach it what good looks like in this specific context, and the governance that determines when human review is required. If any of those are absent or shallow, the output will reflect it. The agent is producing results consistent with the precision of the input. That is not a malfunction. It is the design working exactly as specified.
The agent is producing results consistent with the precision of the input. That is not a malfunction. It is the design working exactly as specified.
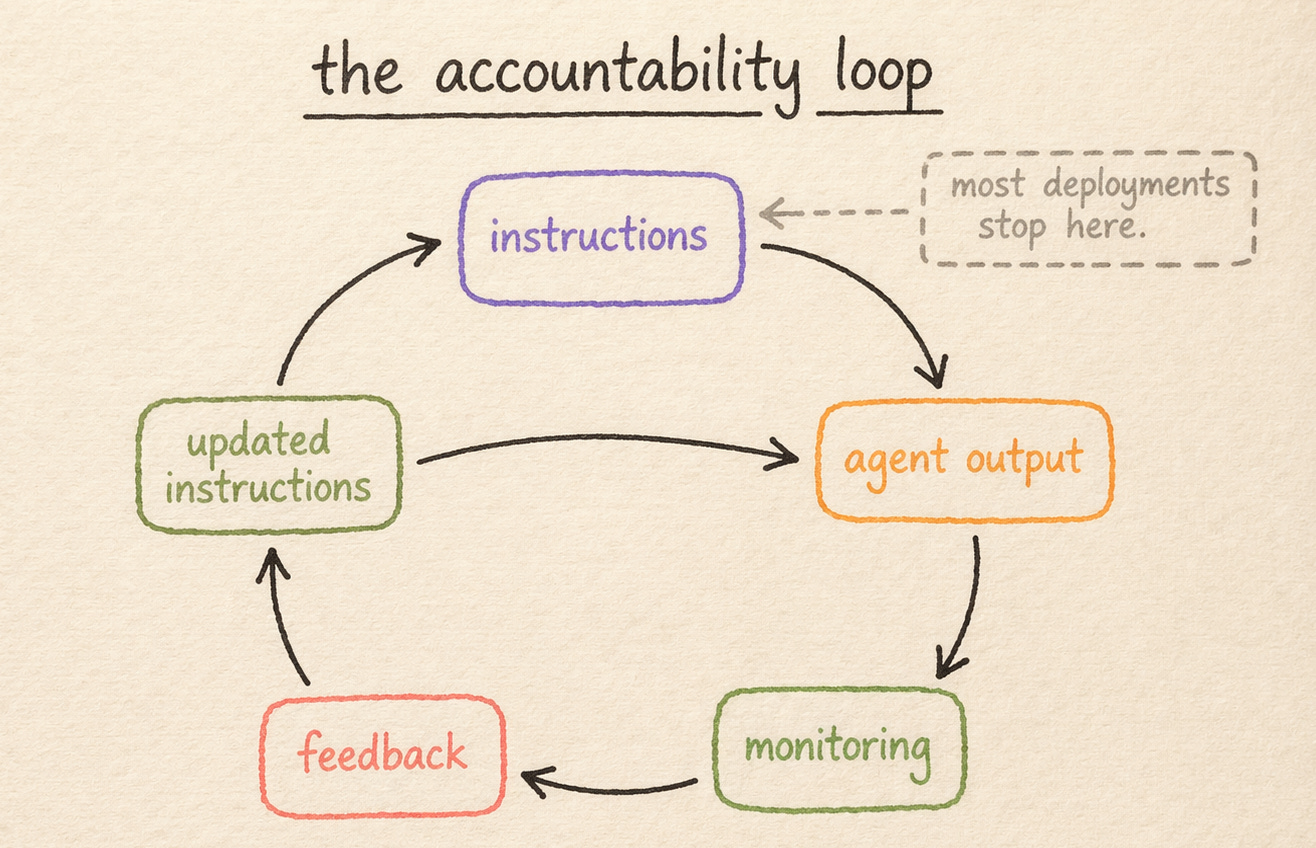
This accountability loop matters more as deployments scale. A single agent handling fifty NDAs a month with inadequate instructions is an annoying problem. Ten agents handling five thousand requests a month in the same state is an expensive one, possibly a risk management problem as well. The quality of the instruction system scales with the deployment, which means the investment in precision at the outset is not a nice-to-have. It is the thing that determines whether the deployment has positive or negative expected value.
🔍 What precision actually looks like
What does precision actually look like? I think it is worth being concrete, because “better instructions” can expand to mean almost anything.
At minimum, it means a routing logic document that is actually specific: not “send commercial requests to the commercial team” but a decision tree that reflects how requests actually arrive and what they actually require. Which request types get auto-acknowledged and handled within a defined SLA. Which ones go straight to the GC. Which business units have different protocols because of their risk profile or their history with legal. What happens when a request doesn’t fit a known category. These distinctions already exist in every mature legal team. They live in people’s heads, in the judgment calls that senior lawyers make every morning without articulating them, in the tribal knowledge that takes a new team member six months to absorb by osmosis. The work of onboarding an agent is, in significant part, the work of surfacing that institutional logic and making it explicit. That is hard work. It is also work that would have been worth doing regardless of the agent deployment, because knowledge that lives only in individual people’s heads is fragile in ways that compound as teams grow and change.
Knowledge that lives only in individual people's heads is fragile in ways that compound as teams grow and change.
It also means a structured monitoring period. Not permanent review, not a lack of trust in the system, but a disciplined early period. The first month of deployment should probably involve a lawyer reviewing a sample of agent outputs against the playbook. Not because the agent cannot be trusted, but because no playbook is complete when you write it. The gaps show up in the output. Reviewing that output is how you find the edge cases you didn’t anticipate, which lets you update the instructions before those gaps compound into a pattern the team notices and misattributes to poor accuracy.
And it means measurement from the start. Which categories of request is the agent handling well? Where is it escalating more than expected, and where less? Is the escalation rate changing as the playbook matures? Without a measurement framework, you cannot distinguish between an agent that is improving and one that is quietly producing worse output that nobody is catching. Two-thirds of enterprises, per the ModelOp data, are still in this state with their production AI.
The reins can be gradually released. But only if someone is watching while they are still held.

The discipline that comes next
I think the teams that get this right will not necessarily have access to better models or larger budgets. What they will have done differently is approach the deployment with the same rigour they would apply to building and managing a team: clear expectations at the outset, feedback during the ramp, monitoring until trust is justified, and accountability that sits with the people who designed the system rather than with the system itself.
The market has shifted noticeably in the past few months. The dominant question from legal teams is no longer “can AI do this at all?” but “what can it actually do?” The disbelief phase is largely over. What comes next is harder, and I think less discussed: the operational discipline of building agent systems that are actually trustworthy, which requires treating instructional precision as a management competency rather than a configuration step.
The teams that succeed will approach the deployment with the same rigour they would apply to building and managing a team. Accountability will sit with the people who designed the system rather than with the system itself.
Agents do what you tell them to do. That is not a limitation. It is the design. The question is whether what you told them is precise enough to produce the output you needed, and whether you are honest with yourself about the answer when it isn’t.
✳️
Thanks for reading! Subscribe for free to receive new insights, and check out flank.ai for more information on how you can deploy agents in your enterprise.