Legal AI has an infrastructure problem

Why 52% of legal teams adopted AI but almost none reduced costs, by Martin Lukac
The number nobody is talking about
Anthropic published something this month that I think deserves more attention from the legal industry than it has received. Their researchers, Maxim Massenkoff and Peter McCrory, introduced a framework for measuring AI’s actual impact on the labour market, as distinct from its theoretical potential. The study is called “Labor market impacts of AI: A new measure and early evidence”, and its core contribution is a metric they call “observed exposure”.
The distinction matters. Theoretical exposure measures whether an AI system could, in principle, perform a task well enough to double the speed of completion. Observed exposure measures whether anyone is actually using it that way. The gap between those two numbers turns out to be enormous. And for legal work specifically, I think that gap explains more about the current state of the market than any product announcement or funding round.
🔍 What the study found
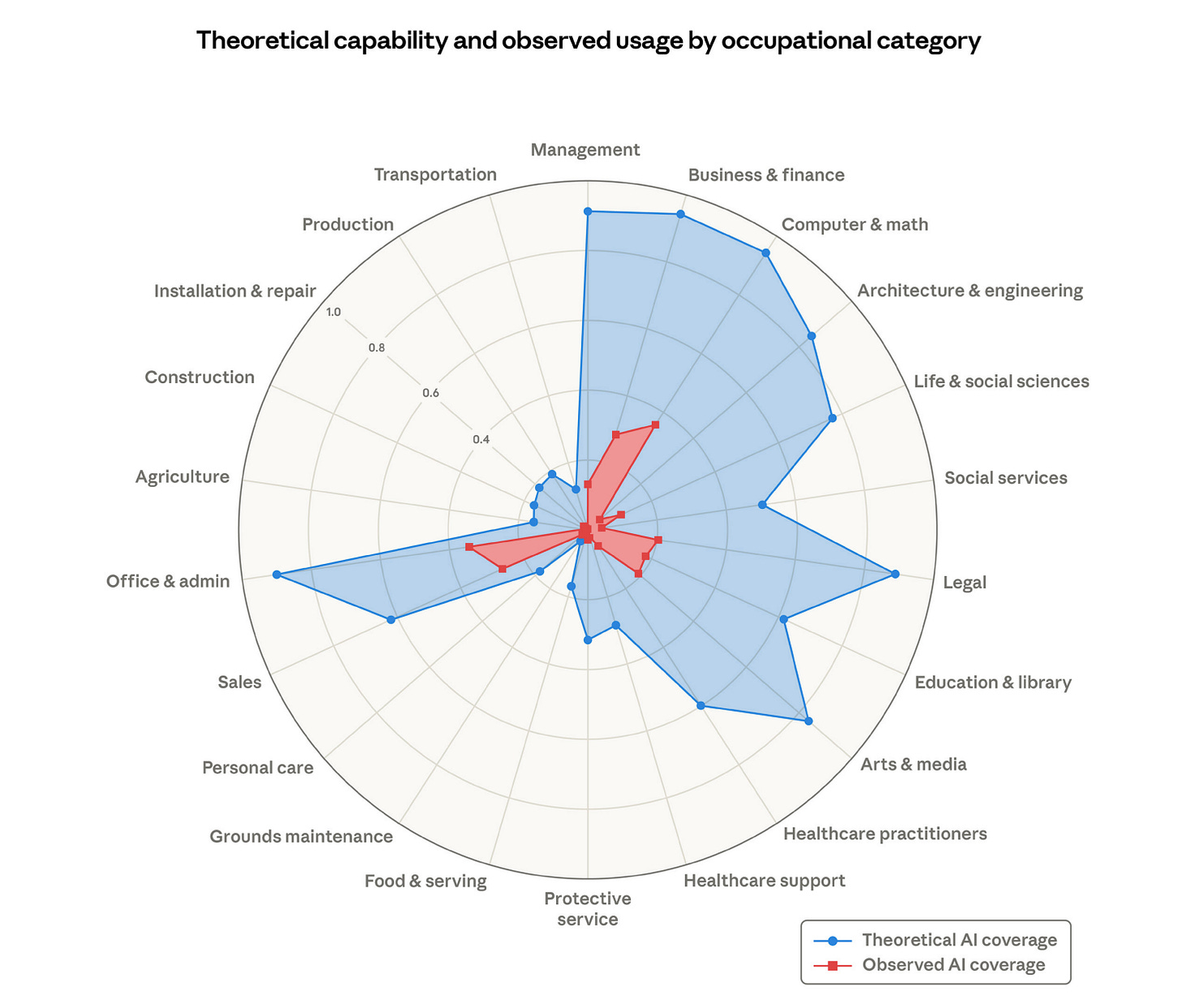
The researchers combined three data sources: the O*NET database of approximately 800 US occupations and their associated tasks, Anthropic’s own usage data showing how Claude is actually being used in professional contexts, and earlier task-level exposure scores from Eloundou et al. that rate theoretical AI feasibility.
The headline finding is that 97% of observed Claude usage falls within tasks that are theoretically feasible for language models. The models are being used for things they are genuinely good at. But the coverage is wildly uneven. Computer programmers show 75% task coverage. Customer service representatives show substantial exposure. And 30% of workers have zero measurable coverage at all. Not because AI cannot do parts of their job. Because nobody has built the systems, workflows, and deployment architectures that would let it.
The demographic profile of the most-exposed workers is the part that should concern legal teams. High-exposure workers are, on average, older, more educated, and higher-paid. They earn approximately 47% more than their unexposed counterparts. Graduate degree holders make up 17.4% of the most-exposed group versus 4.5% of the unexposed. This is, more or less, a description of the in-house legal profession.
30% of workers have zero measurable coverage at all. Not because AI cannot do parts of their job. Because nobody has built the systems, workflows, and deployment architectures that would let it.
⚡ What it means for legal
The ACC/Everlaw survey found that corporate legal AI adoption more than doubled in a single year, from 23% to 52%. At the same time, only 7% of those teams reported a reduction in total legal spend. 64% expect to reduce their reliance on outside counsel because of AI capabilities they are building internally. The expectation is running decades ahead of the outcome.
I think Anthropic’s framework explains why.
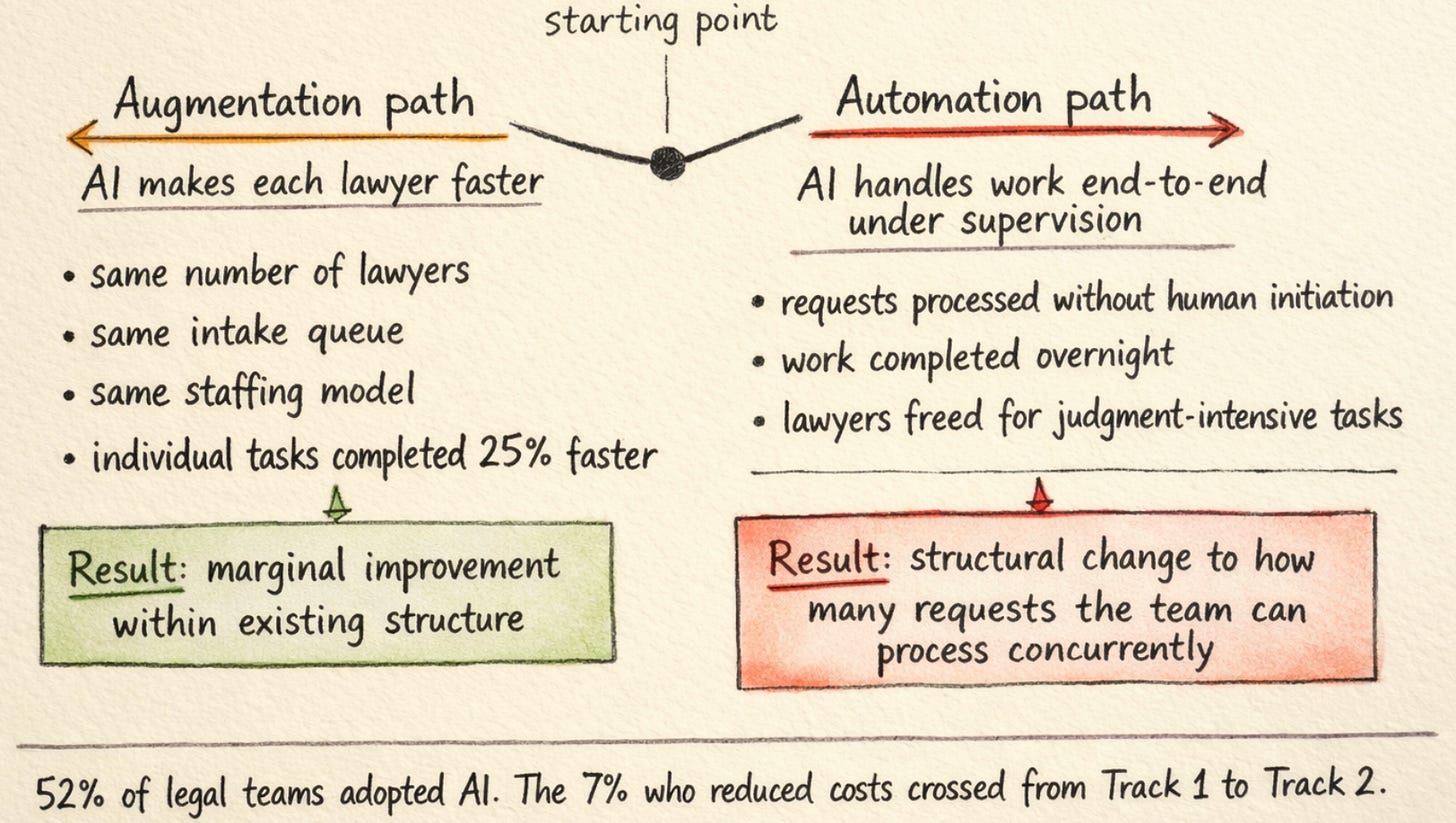
The study makes a deliberate methodological choice that maps directly onto the legal AI market. It weights augmentative use, where AI assists a human who still does the work, at 50% of full exposure. Automated workflows, where the AI executes the task end-to-end, receive full weight. The researchers are not treating these as the same thing, because they are not the same thing economically. A tool that makes a lawyer 25% faster on contract review is measurably different from a system that completes the contract review under supervision while the lawyer works on something else.
The legal AI market has spent three years conflating these two categories. The 52% adoption figure captures both. The 7% cost reduction figure captures almost exclusively the second category, because augmentation tools do not change the staffing model. They change the speed of individual tasks within the same staffing model. The constraint on legal team throughput has never been how fast a single lawyer can review a single NDA. The constraint is how many requests the team can process concurrently, which is bounded by how many lawyers are available to pick work up off the pile.
The constraint on legal team throughput has never been how fast a single lawyer can review a single NDA. The constraint is how many requests the team can process concurrently.
Making each lawyer 25% faster is a genuine improvement. The Harvard/BCG study on AI capability confirmed speed gains around that figure, with quality improvements around 40%. Those numbers are real. But faster lawyers do not mean fewer lawyers, any more than faster fax machines meant fewer fax machines. They mean marginally better output within the same structural arrangement.
Where the gap closes
There is a finding in the study that I keep returning to. Post-ChatGPT hiring rates for workers aged 22-25 in exposed occupations dropped approximately 14%. The researchers flag this as tentative, requiring deeper investigation. I find it the most structurally significant datapoint in the paper.
If you accept that the gap between theoretical and observed exposure is primarily an infrastructure gap, a gap between what AI can do in principle and what organisations have built the systems to let it do in practice, then the question becomes: what happens when the infrastructure catches up?
But faster lawyers do not mean fewer lawyers, any more than faster fax machines meant fewer fax machines.
The BLS growth projections in the study show employment growth declining by 0.6 percentage points for every 10-point increase in AI coverage. The 14% hiring drop for young workers in exposed occupations is consistent with that trajectory. The mechanism is not that AI is replacing existing workers. The mechanism is that the entry-level pipeline is narrowing because the volume work those roles used to handle is being absorbed by systems that can process it without human initiation.
For the legal profession, this is not a hypothetical. The work that junior lawyers have traditionally been hired to do, first-pass NDA reviews, standard template drafting, triage of routine requests, is precisely the work where the gap between theoretical and observed exposure is closing fastest. Not because the models got dramatically better this year, although they did. But because the deployment infrastructure caught up. Email-native agents that pick up requests from a shared inbox, review against a playbook, and route completed work to a supervision queue are not a research prototype. They are in production at enterprise legal teams processing thousands of requests per month.
Not because the models got dramatically better this year, although they did. But because the deployment infrastructure caught up.
🧠 What the gap is made of
Most enterprise buyers evaluating legal AI are still measuring theoretical exposure. They benchmark model accuracy. They compare hallucination rates. Stanford’s recent study found that Lexis+ AI hallucinates in more than 17% of queries, and Westlaw’s AI-Assisted Research in more than 34%. These numbers deserve scrutiny, but they are measurements of model capability, not system capability. A model that hallucinates 17% of the time inside a chat interface is a different risk profile from an agent that grounds its responses in a specific organisation’s playbook, runs confidence scoring against the team’s risk thresholds, and routes low-confidence outputs to a supervision queue before anything reaches the business. The hallucination rate of the model has not changed. The hallucination rate of the system has.
The hallucination rate of the model has not changed. The hallucination rate of the system has.
The timeline on all of this is genuinely unclear. Suleyman has suggested most legal tasks will be fully automated within 12-18 months. Forrester predicts 25% of planned AI spend will be deferred to 2027. Gartner projects that over 40% of agentic AI projects will be cancelled by end of 2027 due to escalating costs or unclear business value. These predictions are not easily reconciled, and the Anthropic researchers themselves note their findings are early-stage, comparing AI’s labour market impact to gradual disruptions like internet adoption rather than sudden shocks.
What I find clearer than the timeline is the nature of the gap itself. It is not a capability gap. It is an infrastructure gap. The models can already do the work. The question is whether the systems around them can handle the operational reality of how legal work actually arrives: messy documents with three layers of tracked changes, email threads that reference side conversations, counterparty redlines made without revision tracking enabled. Closing that gap is an engineering problem, not a model problem. And the teams that close it first will have a structural advantage that compounds, because every supervision correction improves the system, every deployment teaches the infrastructure something new, and every month of production data makes the next one faster.
The question is whether the systems around them can handle the operational reality of how legal work actually arrives. Closing that gap is an engineering problem, not a model problem
The 7% who have already achieved cost reductions are, I suspect, the teams measuring outcomes at the system level rather than the model level, teams that crossed from augmentation to automation. For everyone else, the question is not whether AI can do their routine work. Anthropic’s own data shows it already does, for the organisations that have built the systems to let it. The question is how long the gap persists in your specific team, and what the cost of that gap is, measured in deals that waited, requests that sat in queues, and capacity that could have been freed for work that actually requires human judgment.
✳️
Thanks for reading! Subscribe for free to receive new insights, and check out flank.ai for more information on how you can deploy agents in your enterprise.