Same engine, different machine

Why better AI doesn't mean a better model, by Martin Lukac
Better AI ≠ better model
There is a peculiar thing happening with AI and legal work right now that I think deserves more attention than it gets. Everyone, every product, every startup, every in-house team experimenting with automation, is building on essentially the same foundation. The LLMs underneath are a small handful of models from a small handful of providers. Opus 4.6, GPT 5.4, Gemini 3.1. You can access them through an API for a few cents per call. A summer intern with a credit card can spin up a contract review prototype in an afternoon.
And yet there is a staggering difference in what comes out the other end.
🔍 I find this worth thinking about carefully, because I think the intuition most people carry, that “better AI” means “better model,” is wrong in a way that matters. The model is a reasoning engine. It can hold a long document in context, trace conditional logic across clauses, identify where a term deviates from a standard position. These are real capabilities, and they have improved dramatically in the past eighteen months. But a reasoning engine is not a legal agent, in the same way that an engine is not a car. What you build around the engine determines whether the output is something a lawyer would trust enough to put in front of a counterparty, or something that looks plausible but falls apart the moment it encounters the operational reality of how legal work actually happens.
“better AI” means “better model,” is wrong in a way that matters
The gap nobody demos
Here is a scenario that clarifies the problem. A counterparty sends back redlines on your MSA. The document has three layers of tracked changes, some accepted, some pending. A paragraph was copied from a different template and arrived in a different font. Two clauses were edited without tracked changes turned on, so the modifications are invisible unless you compare against the original. The email thread references a side conversation about a carve-out that changes the meaning of Clause 7.
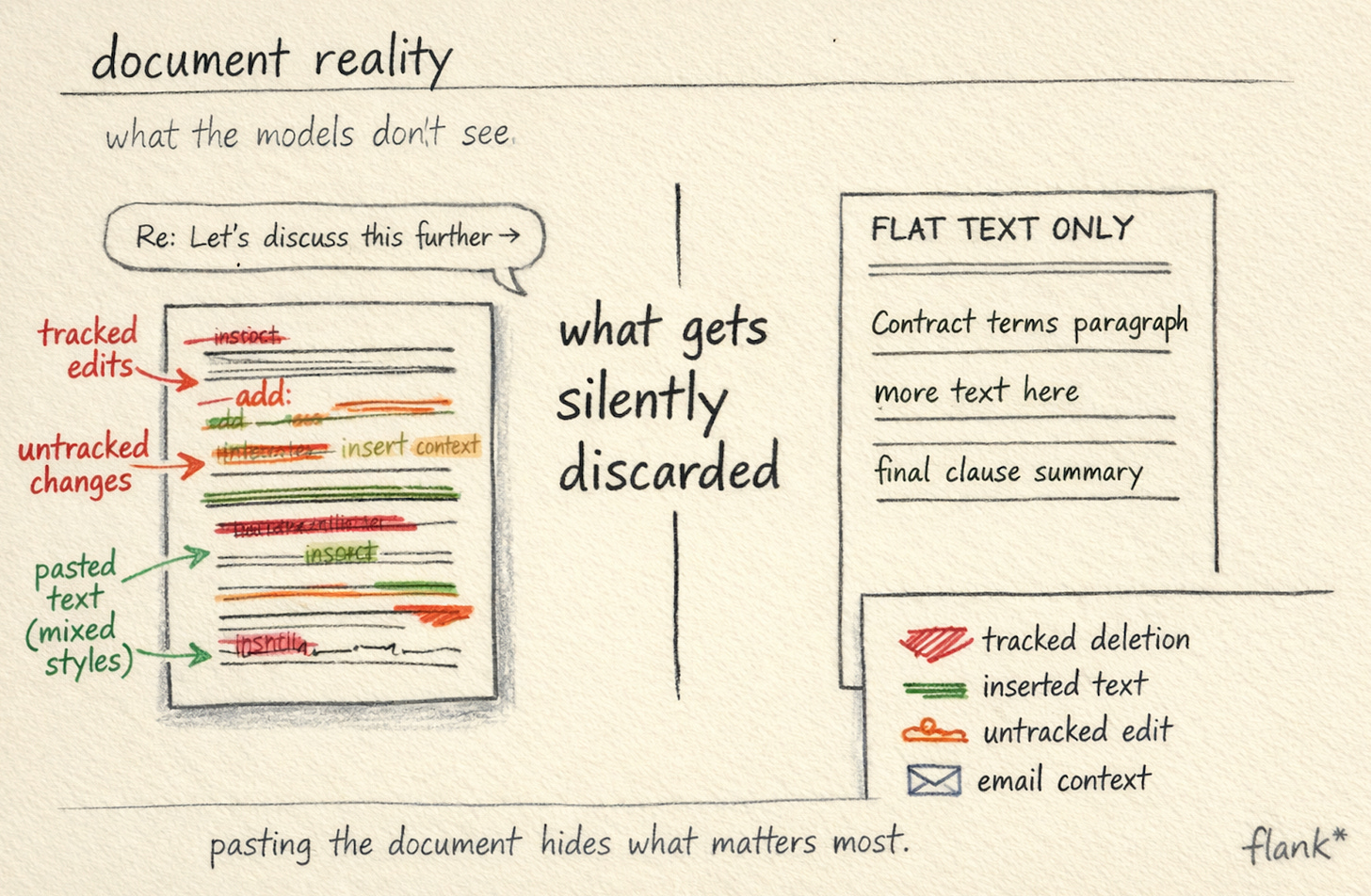
Most people assume the hard part here is the legal reasoning. It is not. The hard part is the document itself.
If you have ever wondered what is hiding under a .docx file, a .docx file is a ZIP archive containing XML. Tracked changes are represented as inline markup elements, insertions, deletions, format changes, each tagged with author and timestamp metadata. The OOXML specification defines 28 distinct elements for tracked revisions, each with their own semantics. When a counterparty accepts some changes, rejects others, and then edits directly without revision tracking enabled, the resulting XML is a palimpsest. The “current” state of the document is not stored anywhere as a clean text. It has to be reconstructed by walking the revision tree. When someone pastes content from a different template, the XML inherits the source document’s style definitions, paragraph properties, and numbering schemes, which may conflict with the target document’s own definitions in ways that are invisible in the rendered view but structurally significant at the markup level.
Most people assume the hard part here is the legal reasoning. It is not. The hard part is the document itself.
If you paste this document into a chat interface and ask an LLM to review it, you are handing the model a flat text extraction that has silently discarded all of this structure. The untracked changes are invisible, because detecting them requires comparing the document’s XML against the original template at the element level, not just reading what the rendered document says. The model will produce a review that sounds like legal reasoning but is grounded in an input that does not accurately represent what the document actually proposes.
Why 70% accuracy is dangerous
The output is 70% of the way there. For a demo, 70% is impressive. For production, 70% is dangerous. A lawyer who trusts that output and sends it to a counterparty has just negotiated away from their own playbook without realising it.
🔍 This is the gap that I think most conversations about legal AI skip over. The question is not “can an LLM reason about law?” It can. The question is whether the system around the LLM can navigate the messy operational reality of how contracts arrive, how edits get tracked (or don’t), how business context from an email thread changes the meaning of a clause, and how the output needs to conform not to generic legal standards but to a specific organisation’s templates, preferred terms, and escalation rules.
The output is 70% of the way there. For a demo, 70% is impressive. For production, 70% is dangerous.
Why the commodity model makes products more valuable, not less
There is a counterintuitive dynamic at work here. As models become cheaper and more accessible, the reasoning engine itself becomes closer to a commodity. The evidence for this is now fairly concrete. The most widely cited independent benchmark for comparing language models is the LMSYS Chatbot Arena, where humans blind-test model outputs head to head. The top ten models are now so close in performance that the differences between them are statistically marginal. Opus 4.6 and Gemini 3.1 Pro are, for practical purposes, indistinguishable. The gap is narrow enough that the model which performs best on your specific task depends more on how you use it than on which one you chose.
I think this means the value has shifted, almost entirely, to the product layer. And I want to be specific about what “product layer” means in engineering terms, because the phrase is too often used as a hand-wave.
It means a document processing pipeline that operates on the OOXML structure rather than on a flat text extraction, one that can reconstruct the net state of a redlined document, detect untracked modifications by diffing against a reference version, and preserve the structural metadata that the legal reasoning layer needs. It means a retrieval architecture that grounds the agent in a specific team’s playbook, clause library, and precedent positions, not by stuffing a prompt with context, but through a retrieval system designed to surface the right fallback language for the right clause type in the right jurisdiction. The gap between a naive retrieval setup and a domain-tuned one is significant enough that McKinsey’s 2025 State of AI survey found only 6% of organisations qualify as “AI high performers” generating meaningful returns from their AI investments, despite 71% reporting regular use. The retrieval layer, and the institutional knowledge it encodes, is a large part of what separates the 6% from the rest.
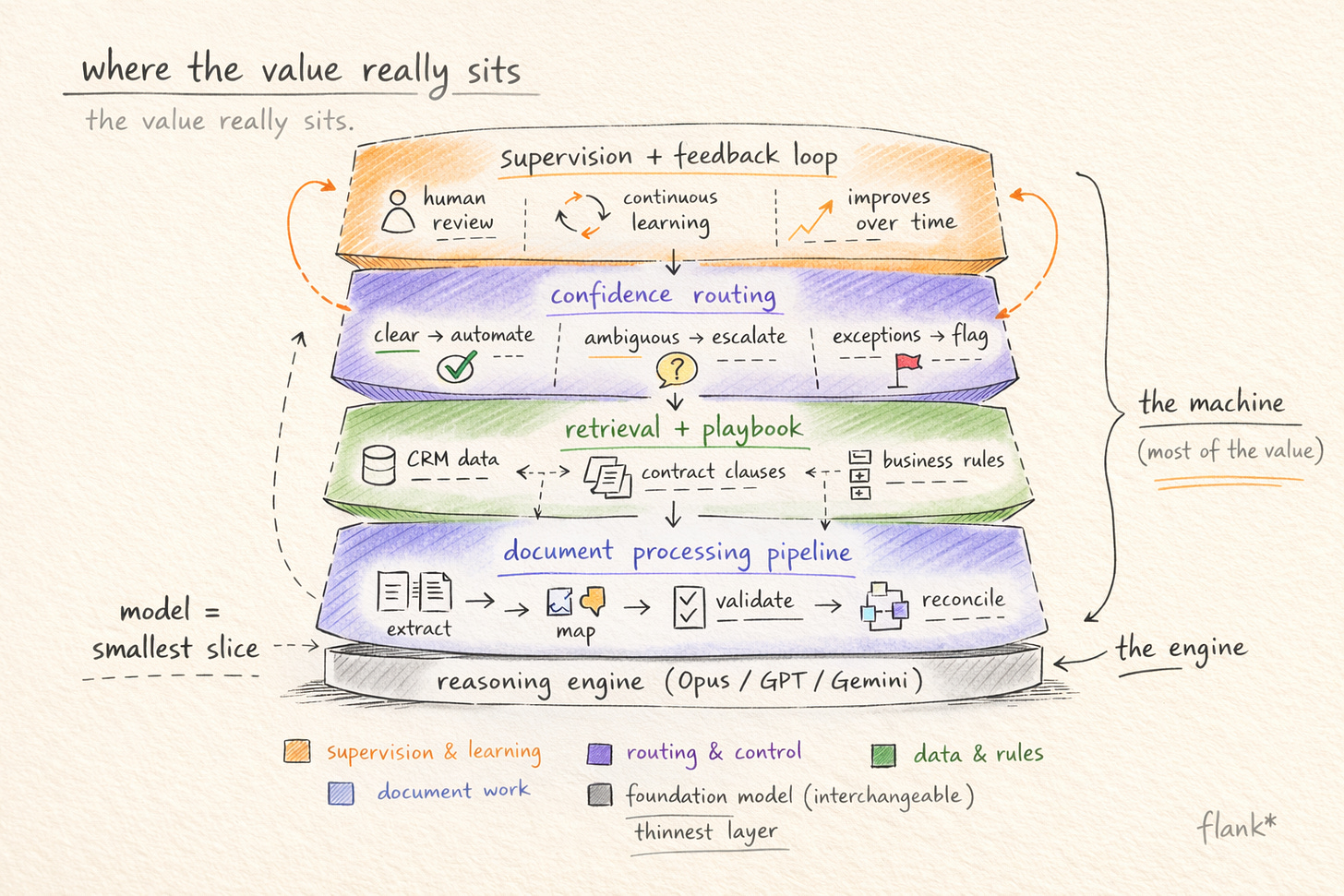
It also means the feedback loop where a supervisor’s correction on Tuesday improves the agent’s output on Wednesday. And it means the confidence estimation system that determines whether a given output routes to a supervisor at all, or goes directly to the business user, which is a harder engineering problem than it sounds. Language models are, by default, poorly calibrated on their own uncertainty. They express high confidence even when the underlying reasoning is thin. Building a system that reliably distinguishes between “this NDA is completely standard and the agent’s output can go straight to the requestor” and “this indemnification clause deviates from playbook in a way that needs a lawyer’s eye” requires engineering beyond the model itself: task-specific confidence scoring, threshold tuning against the team’s actual risk tolerance, and continuous recalibration as the agent encounters new document patterns.
✳️ None of this is model capability. All of it is product.
And yet the conversation in most procurement rooms is still about which model the product uses, as if that were the differentiator. I find this roughly analogous to evaluating cars by asking which company supplied the steel. It is not irrelevant. It is just not where the meaningful differences live.
What production-quality actually requires
There is a specific bar that legal work needs to clear before it can move from experiment to production, and I think it is worth naming precisely. The bar is not “accurate.” Accuracy is necessary but insufficient. The bar is: output that a supervising lawyer recognises as consistent with how their team actually works, and that the system itself knows when to route for review rather than sending directly.
This is a higher standard than it sounds. It means the agent selects the right template for the jurisdiction. It means the fallback language in a counter-redline matches the playbook position the team has agreed on, not a plausible alternative the model invented. It means the agent knows that Document X supersedes Document Y when they conflict, because someone configured that rule, not because the model inferred it. It means the review summary uses the structure the team expects, flags the categories of risk the team cares about, and escalates the issues the team has defined as requiring human judgment.
The bar is not “accurate.” Accuracy is necessary but insufficient. The bar is: output that a supervising lawyer recognises as consistent with how their team actually works
A chat interface, no matter how well prompted, does not have access to any of this. It does not know the team’s playbook. It does not know the escalation thresholds. It does not know that the GC wants to see anything involving IP assignment before it goes out, but is comfortable letting NDAs with standard terms go directly to the business. This is not a prompting problem. It is a systems problem.
🧠 The most significant engineering consequence of this is what happens after the output is generated. In a chat setup, the output arrives and the lawyer reviews it. Whatever the lawyer corrects, the system does not learn from it. The next time a similar request comes in, the same mistakes will appear. In a system with a supervision architecture, corrections feed back: into the retrieval index, into the confidence thresholds, into the routing logic. Over time, the agent’s behaviour converges with the team’s preferences rather than with generic legal reasoning. The lawyer’s role shifts from operator to supervisor, and the constraint on throughput shifts from available headcount to available compute, which is, for practical purposes, uncapped.
What I think is genuinely uncertain
I do not want to overstate the clarity of where this is heading. I find the direction clear: the gap between raw LLM capability and enterprise-grade legal automation is a product problem, not a model problem, and the teams that invest in the product layer will have a structural advantage. What I am less certain about is the competitive dynamics.
There is a real possibility that buyers continue to evaluate legal AI primarily on model capability for another year or two, because model capability is easy to benchmark and product depth is hard to evaluate without actually deploying it. There is also a possibility that the foundation model providers move further up the stack, packaging legal-specific workflows directly. Anthropic has already started doing this. The question is whether a general-purpose platform, however good the underlying model, can encode the same depth of domain logic as a system built specifically to handle the 28-element tracked changes specification, the jurisdictional variation in fallback positions, the confidence calibration against a specific team’s risk appetite. My view is that the gap is structural, not incremental, and that plugins and workflow templates do not close it. But I recognise that foundation model providers have surprised people before, and the speed at which they are moving into vertical applications makes this the most consequential open question in the market right now.
What I keep returning to is the scenario. A counterparty sends back redlines. The document is messy. The business context matters. The team’s playbook defines the acceptable positions. The system needs to know what it knows and what it does not, and route accordingly. A correction today needs to improve the output tomorrow. Every part of that chain is a product problem. The model is the engine. The machine is everything else.
And right now, the machines are very different.
Learn what's possible at flank.ai.