We gave an agent our hardest problem

Why enterprise contract complexity is no longer a ceiling for AI agents, by Paul Lacey
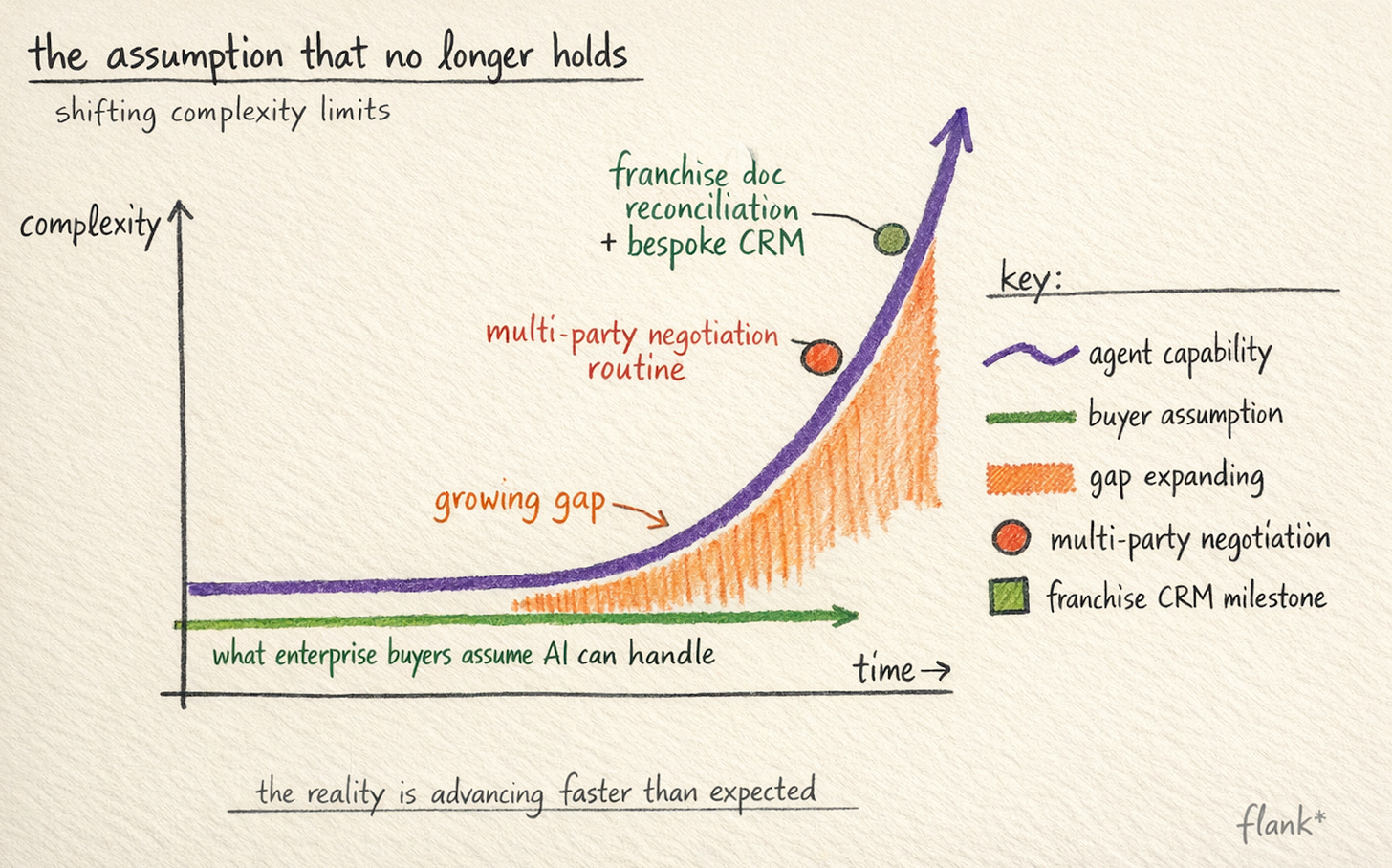
The assumption that no longer holds
Last month we ran a proof of concept with a global enterprise that, on paper, should not have worked as smoothly as it did. The task was to take a set of business-critical contracts, franchise agreements running to 80 or 100 pages each, and reconcile the data inside them against the company’s CRM. The CRM was not a simple database. It had been built over years to capture the full complexity and variability of a global business: dozens of fields, layered conditionality, regional variations, edge cases stacked on edge cases. The kind of system where the schema itself tells a story about how complicated the underlying commercial relationships actually are.
In the old world, this is work you would pay a consultancy to do. The engagement would be called something like a “mapping exercise,” and it would involve weeks of discovery, a team of analysts building a reconciliation layer between the contract data and the CRM fields, and a deliverable that was, in practice, a brittle tool requiring its own headcount to maintain. I have seen these projects quoted at figures that make you wonder whether the consultancy is solving the problem or just making it expensive enough that nobody questions whether it was solved.
In the old world, this is work you would pay a consultancy to do.
We set up a bespoke agent task to do the reconciliation. Even having spent the past two years watching agents handle progressively harder legal work, I was genuinely surprised at how easily the agent navigated the massive data structure. It surfaced inconsistencies between the contract terms and the CRM records. It handled conditional fields that depended on jurisdiction, deal type, and commercial terms that varied across regions. And when it encountered something genuinely ambiguous, where the contract language and the CRM schema did not clearly correspond, it said so. It flagged the uncertainty, explained why it was uncertain, and asked for human input.
That last part is the one I keep thinking about.
The assumption that needs updating
There is a default assumption among enterprise buyers, one that I hear in almost every early conversation, that certain categories of work are simply too complex for AI agents. The reasoning usually goes something like: our contracts are highly variable, our data structures are bespoke, our business logic has dozens of conditional branches, therefore this is fundamentally a human-judgment problem. The implicit model is that AI is good at pattern-matching on simple, repetitive tasks, and that complexity creates a ceiling the technology cannot reach.
I think this assumption made sense eighteen months ago. It does not make sense now, and the gap between the assumption and the reality is widening fast.
The shift is partly about model capability. The foundation models available today, Opus 4.6, GPT 5.4, Gemini 3.1, are qualitatively different from what was available even a year ago in their ability to reason about complex, conditional, multi-dimensional information. A franchise agreement with 80 pages of interlocking terms and regional variations is, from the model’s perspective, a structured reasoning problem. The model can hold the full document in context, trace the conditional logic across clauses, and identify where the contract’s terms map to external data structures and where they don’t. It does this without getting tired, without forgetting a clause it read forty pages ago, and without the implicit biases that come from a human analyst who has seen a hundred similar documents and unconsciously assumes this one follows the same pattern.
The foundation models available today, Opus 4.6, GPT 5.4, Gemini 3.1, are qualitatively different from what was available even a year ago in their ability to reason about complex, conditional, multi-dimensional information.
But the shift is also about something less obvious, which is what happens when you design an agent to operate on a specific customer’s data rather than on generic legal knowledge. The proof of concept worked not because the model is generically smart, but because the agent was configured to understand the specific CRM schema, the specific contract structure, and the specific business logic that connects them. That configuration work, building the bridge between the model’s reasoning capability and the customer’s actual data environment, is where the real product lives.
Why the old approach was so expensive
It is worth thinking about why the consultancy model for this kind of work costs what it costs, because I think it reveals something about the nature of the problem that matters for understanding why agents handle it well.
A mapping exercise between complex contracts and a complex CRM is expensive not because the individual data points are hard to extract. Most of the fields, taken in isolation, are straightforward: a date, a territory, a fee structure, a renewal term. The expense comes from the combinatorial complexity of the relationships between fields. Field A means one thing when Field B has value X, and something different when Field B has value Y, and something different again when the contract was executed under jurisdiction Z. The human analyst has to build a mental model of these relationships, verify it against the actual data, and encode it into a reconciliation tool that can handle the full range of variations.
This is exactly the kind of work that humans are bad at and that language models are good at. Humans are excellent at judgment, at spotting when something feels wrong, at making calls in genuinely ambiguous situations. They are less excellent at holding dozens of conditional relationships in working memory simultaneously and applying them consistently across hundreds of pages of text. The fatigue factor alone makes human-driven mapping exercises inherently error-prone at scale. By the third day of reviewing franchise agreements, the analyst’s attention to the conditional logic in clause 14.3(b)(ii) is not what it was on the first morning.
This is exactly the kind of work that humans are bad at and that language models are good at. Humans are excellent at judgment, at spotting when something feels wrong, at making calls in genuinely ambiguous situations. They are less excellent at holding dozens of conditional relationships in working memory […].
The consultancy model compensates for this with process: multiple reviewers, quality checks, reconciliation passes. All of which add cost and time without fundamentally changing the cognitive limitation that created the problem. The deliverable, the mapping tool or reconciliation spreadsheet, captures whatever the team understood at the point of delivery. It does not update when the contracts change, when the CRM schema evolves, or when a new regional variation enters the portfolio. Maintaining it requires the same kind of careful, context-dependent work that built it, which is why these tools tend to degrade over time unless someone is permanently assigned to keep them current.
What actually happened in the POC
I want to be specific about what the agent did, because I think the detail matters more than the summary.
The task was structured as a reconciliation: given this contract and this CRM record, identify where the data aligns, where it diverges, and where the mapping is ambiguous. The contracts were franchise agreements, which are among the more complex document types in commercial legal work. They contain financial terms that vary by territory, operational requirements that depend on the type of franchise, renewal and termination provisions with multiple conditional triggers, and schedules that cross-reference the main body in ways that are not always consistent.
The CRM, meanwhile, had been built to mirror this complexity. It was not a simple flat table of deals. It was a deeply nested structure with its own conditional logic, designed to capture the variability of a global franchise operation across dozens of markets. Anyone who has worked with enterprise CRMs knows the feeling: the system is doing exactly what it was designed to do, and what it was designed to do is reflect a business that is genuinely complicated.
The agent processed the documents, mapped the contract fields to the CRM fields, and produced a structured reconciliation output. Where the data matched, it confirmed the match. Where it diverged, it identified the specific discrepancy: this contract says the renewal term is five years, the CRM says three, here is where each value appears. Where the mapping was ambiguous, it didn’t guess. It explained what it found, why the correspondence was unclear, and what a human would need to resolve.
The ambiguity handling is the part that I find most significant. Enterprise buyers worry, reasonably, about AI systems that are confidently wrong. A system that processes a complex contract and returns a clean, confident output is useful if the output is correct and dangerous if it isn’t. What we saw in this POC was an agent that had a calibrated sense of its own uncertainty. When the data was clear, it was decisive. When the data was genuinely ambiguous, where the contract language could plausibly map to more than one CRM field, or where a conditional clause made the correct mapping depend on information not present in the document, it surfaced the ambiguity rather than resolving it silently.
What we saw in this POC was an agent that had a calibrated sense of its own uncertainty.
This is not a trivial capability. Building a system that knows what it doesn’t know, and communicates that clearly enough for a human to act on it, is arguably harder than building one that gets the right answer most of the time. It is also, I think, the capability that matters most for enterprise adoption. The GC or legal ops lead who is evaluating whether to deploy agents on business-critical contracting is not primarily worried about the 90% of cases where the answer is obvious. They are worried about the 10% where it isn’t, and whether the system will handle those cases in a way that protects the business rather than exposing it.
The complexity ceiling is a moving target
The broader pattern I am seeing, across this POC and across other deployments, is that the boundary between “too complex for AI” and “actually, agents handle this well” is moving faster than most buyers have updated their mental model.
Twelve months ago, multi-party contract negotiation with conditional fallback positions was genuinely at the edge of what agents could reliably do. Today, it is routine production work for well-configured deployments. The franchise document reconciliation would have been a stretch even six months ago, not because the models couldn’t reason about the data, but because the tooling to configure agents against bespoke enterprise data structures was not mature enough to make it practical. The fact that it worked in a POC, with the agent navigating a genuinely complex CRM schema and producing useful, calibrated output, tells me the ceiling has moved again.
The boundary between “too complex for AI” and “actually, agents handle this well” is moving faster than most buyers have updated their mental model.
I think this matters for how enterprise legal teams think about their automation strategy. The common approach is to start with the simplest, most standardised work, NDAs, basic vendor agreements, routine triage, and defer anything complex to “phase two” or “when the technology is ready.” That sequencing made sense when the technology genuinely couldn’t handle complex work. It makes less sense now, and I find that teams who are willing to test agents on their harder problems are often surprised by the results.
This is not to say that agents can handle everything. There are categories of legal work that require genuine human judgment in ways that are not reducible to reasoning about text and data: strategic advice, novel legal questions, negotiations where the commercial context matters as much as the contractual terms. The point is not that the ceiling has disappeared. It is that it is significantly higher than most people assume, and it is still rising.
What this means for the consultancy question
The POC surfaced a question that I think a lot of enterprise buyers are going to face in the next twelve months. If an agent can reconcile complex contract data against a bespoke CRM schema, with calibrated uncertainty and clear handoff to humans on ambiguous cases, what is the consultancy engagement actually paying for?
The honest answer, I think, is that the consultancy was always partly paying for the cognitive work and partly paying for the comfort of having a team of humans responsible for the outcome. The second part is not not
hing. Institutional accountability matters, especially in regulated industries. But the first part, the actual analytical work of mapping complex data structures against each other, is increasingly something that agents do better than human teams. Faster, more consistently, with fewer errors in the routine cases and better-calibrated uncertainty in the hard ones.
The transition will not be instant. Enterprise procurement cycles are long, existing consultancy relationships have inertia, and the trust gap between “this worked in a POC” and “we are comfortable running this in production” is real. But I think the direction is clear. The work that was previously outsourced to consultancies because it was too complex for internal teams to handle at scale is becoming work that agents can do, configured to the customer’s specific data environment, operating under the customer’s supervision, and building the customer’s institutional capability rather than a consultancy’s.
The work that was previously outsourced to consultancies because it was too complex for internal teams to handle at scale is becoming work that agents can do.
We are still in early stages with this specific use case. There is more work to do on production hardening, on scaling the approach across a portfolio of contracts, on building the feedback loops that let the system improve as it encounters new variations. But the proof of concept answered the question we started with. Can agents handle the deep complexity that enterprise buyers assumed was unsolvable? On this evidence, yes. And the fact that the agent’s most impressive capability was knowing when to ask for help, rather than confidently guessing, is the part that makes me think this is not just a demo result.